This entry is part 1 of 3 in the series Databases & UUIDs
- Choose the right primary key to save a large amount of disk I/O
- UUIDs Are Bad for Database Index Performance, enter UUID7!
- Partitioning InnoDB tables by time-based pseudo-sequential UUIDs
Imagine you’re working in a large book warehouse and in charge of new arrivals. There’s a separate, digital system for metadata like authors, categories, etc., so the only information you’ll use during storage is the inventory number. Each book is identified by a unique number with many digits and all books must be findable by their number. To make handling quicker, books are packed in boxes, ordered by the inventory number. When looking for a book, the box must be identified first. Therefore, each box is labeled by the lowest inventory number it contains and the first number that’s in the next box.
Your job in the arrivals room is to pick up books-to-be-stored one by one, assign them a new inventory number in the metadata system, label them by number, and put them in a box as mentioned before. Now, the room is quite small and if you run out of space, you’ll need to move the filled boxes into the basement, which might be two floors down.
The way new inventory numbers are created is important here, and we’ll consider two of the many methods to do it.
1. Roll the dice and generate a completely random number
Considering that the inventory number has many digits, the chance of two books getting the same number is minimal, so this method would work fine. After a book is given its number, it needs to be stored in the correct spot in the correct box. However, because the numbers are generated across the whole range, the book likely needs to go into a box that was already removed from the arrivals room. Therefore, the box will need to be fetched from the basement, and the book placed in it. If the box is already full, it will need to be split into two boxes, each of which will now be about half-empty even after placing the new book. The same process is repeated for each subsequent book.
2. Use a counter and just increase the number by 1 for each book
In this case, boxes can just be filled from start to end, and their order is guaranteed. If a box becomes full, the next books are put into another empty box, until it becomes full as well. The process then repeats, and there’s no need to fetch anything from the basement.
Which one of these two methods will allow the handling of more books per day with the same size arrivals room and a single worker? In this case, the one with the sequential numbers, obviously.
Why are random identifiers even a thing?
Generating random inventory numbers might sound absurd, but there is a security advantage.
Let’s assume that the only information required for fetching a book is its number, and there are multiple clients storing books. If the numbers are sequential, a client might get crafty and try to fetch a book that doesn’t belong to him, by taking his highest inventory number and just adding 1. If the book was not the last in storage, the misbehaving client is guaranteed to get a book that is not their own. In the random system, a client can still guess inventory numbers, but there’s a low chance of getting a correct hit, because there are large gaps between individual inventory numbers, even when they’re in order (remember that the numbers have many digits).1
Another advantage is that random inventory numbers do not give out information about how many books were processed in a given time period.
Indexes in relational databases
The box system as described previously is an analogy for the leaf-level nodes of a B-tree, a data structure commonly used to create lookup indices in relational databases. A B-tree is not limited to one level though. The “boxes” are put into larger boxes with the range also written on them. In this way, not every box needs to be examined when doing a lookup. If there is enough data, the 2nd level can be put into even larger boxes and so on, until there is only a single “root” box that ranges over all of the identifiers in storage.
The problem of inserting records into random places in the leaf nodes still holds though.
When looking at how storage engines are implemented, there are two ways to organize rows in a table’s data space (tablespace):
1. Non-clustered index
The rows in a table using a non-clustered index are written into the tablespace in the order they are received, so there’s no need to access old(er) pages. If it’s necessary to quickly find a row by an identifier, a separate index structure is built that only contains the index values and a pointer to the location of the row in the main data space.
2. Clustered index
All the data is held inside the structure of the primary index. If the access pattern is random, when the pages are retrieved from the disk, they will mostly contain actual record data and not just index values. Data from existing records is useless when inserting new records, but it still takes up space in the page cache. This means that a lesser portion of the table’s rows fit in the cache, compared to when only the index values are stored in the B tree. This leads to more cache misses.
While the random access pattern is not efficient for non-clustered (secondary) indices, it is especially inefficient when the index values only make up a small part of the full row and a clustered index is used.
Experiment and measure!
To demonstrate, I’ve written a smallish test rig that supports three database engines: SQLite, MariaDB (MySQL) and PostgreSQL.
The test script fills a table with the following structure:
| Column | Type | Comment |
| id | BIGINT | Primary key |
| time_created | VARCHAR (64) | Filler data, unimportant |
| data | TEXT (10240) | Random data |
To minimize the impact of data generation and other processes running on the test machine, the main metric I’ve chosen to monitor is the bulk of I/O operations. Compared to a time-based metric, such as sustained inserts per second, it is much more stable.
While disk I/O might not be the bottleneck in all scenarios, computing (CPU) power and network connectivity also matters.
I’ve opted to start the database instances inside Docker containers, so the I/O can be measured using Docker’s stats API.
SQLite
The first tests were done using SQLite, because it supports both options. By default, it uses non-clustered indexes; however, a clustered index can be created for the primary by using the WITHOUT ROWID keyword during table definition.
For each database engine, the page size was set to 16KB, and the page cache size to 10MB.
In the case of SQLite this meant setting the following PRAGMAs:
PRAGMA page_size = 16384; PRAGMA cache_size = -10240;
Non-clustered index
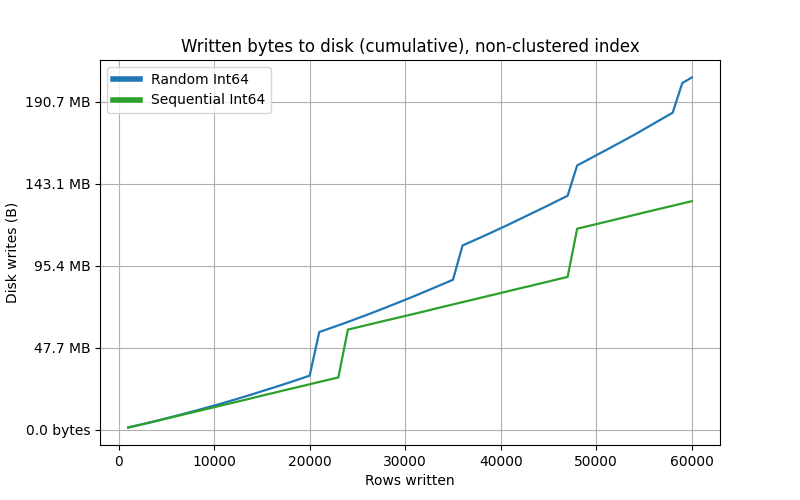
Clustered index
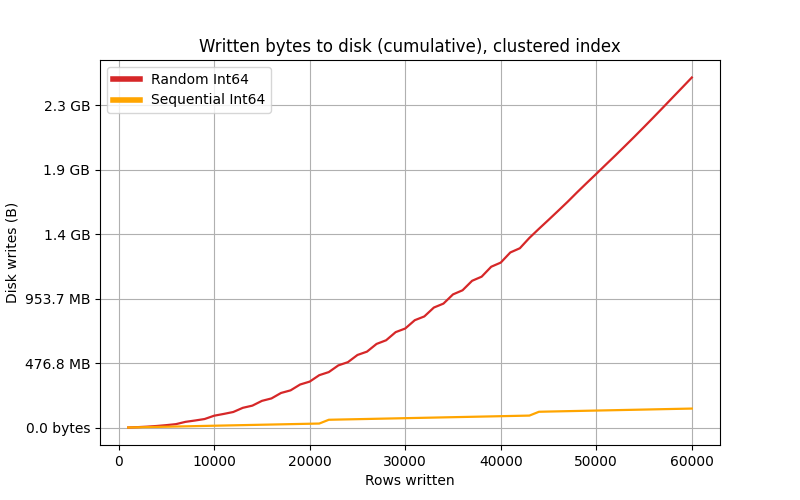
Whoa!
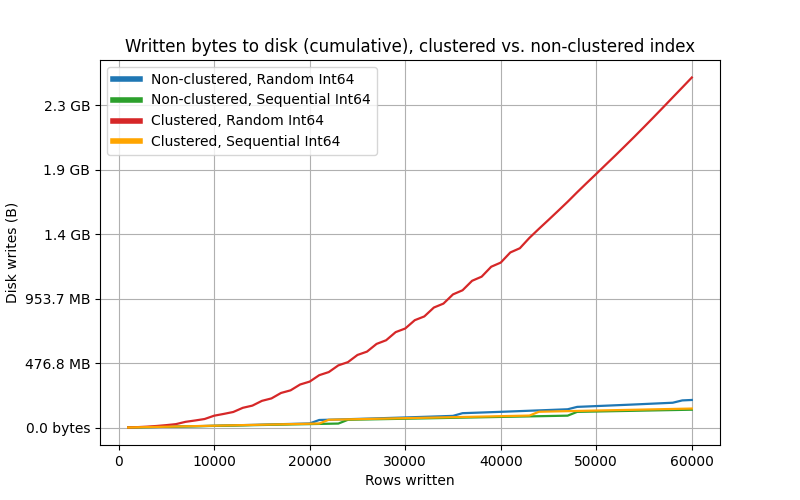
Both clustered and non-clustered in the same plot for comparison:
Graphing writes per one row inserted
By differentiating the series for write volume, we can calculate the write volume needed for a single inserted row.
The data needed some smoothing, but the writes-per-one-row seem to grow logarithmically with the size of the table:
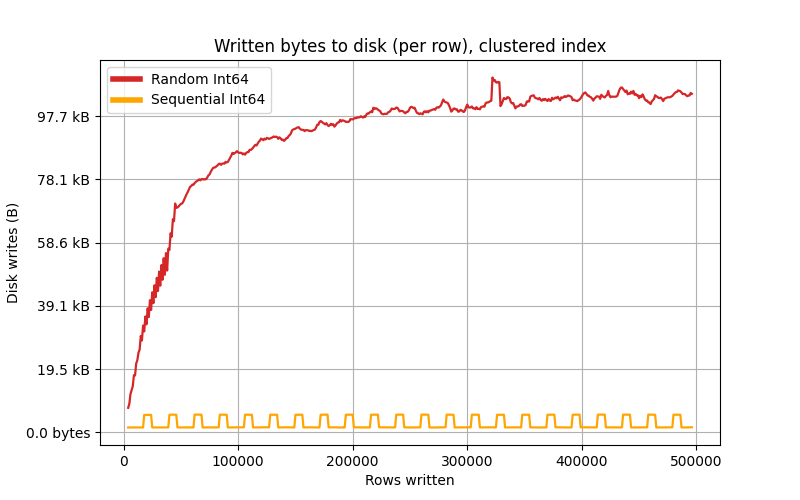
The random primary key’s performance (red) seems to match the B-tree‘s expected insert time complexity of O(log n). Still, we can do much better because pages can be kept in the cache during filling and written out only once (yellow).
MySQL (InnoDB)
The simpler MyISAM storage engine in MySQL is quite limited and doesn’t support transactions. In the current version, InnoDB is the default storage engine and sadly, each table is built around a clustered index.
The following config variables were used to keep the comparisons fair:
innodb_page_size=16k
innodb_buffer_pool_size=10M
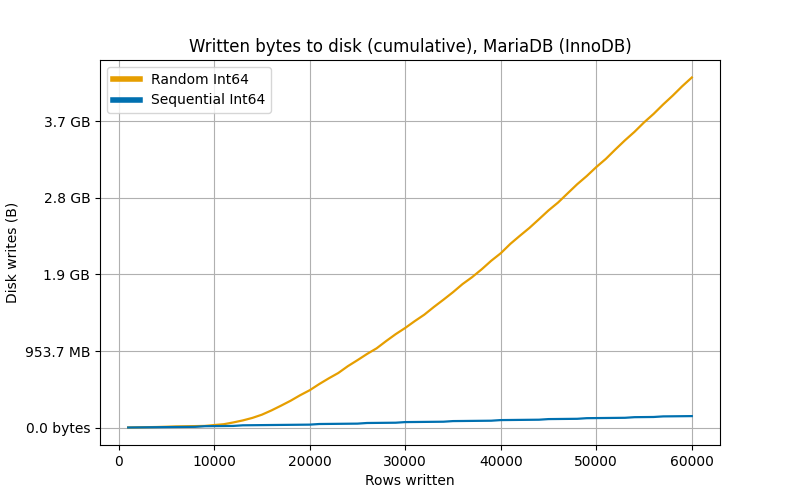
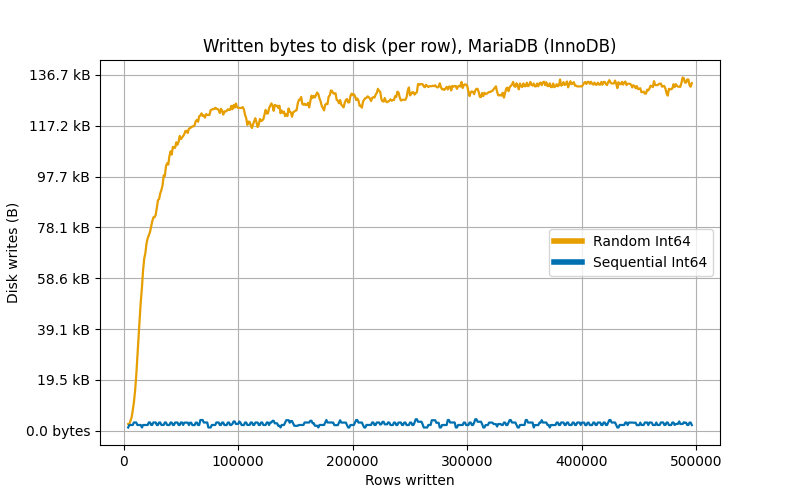
As we can see, InnoDB performs similarly to SQLite’s clustered index.
PostgreSQL
In the case of PostgreSQL, clustered indices are not supported. This can be confusing because a CLUSTER command can be issued, but it is only a one-time operation and will not affect continuous writes.
The impact of random IDs should be much lower and should be similar to SQLite’s default non-clustered index.
As for the setup, PostgreSQL can only change its page size (block size) as a compilation parameter, so I kept the default value of 8KB. I set the page cache (shared_buffers) and WAL size to 10MB by passing the following arguments to the postgres executable:
-c shared_buffers=1280 -c wal_buffers=1280
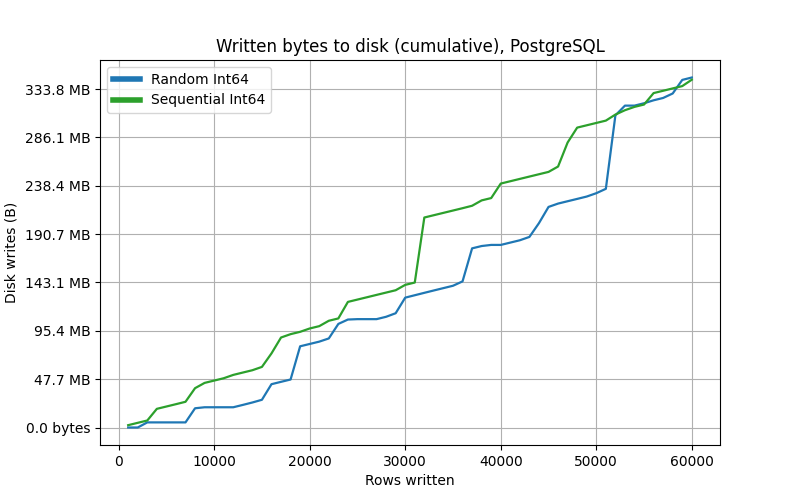
Quite a surprise! It seems that Postgres handles random values better than sequential ones. On a larger scale, though, this relationship switches back to the expected one, where random values “lose:”
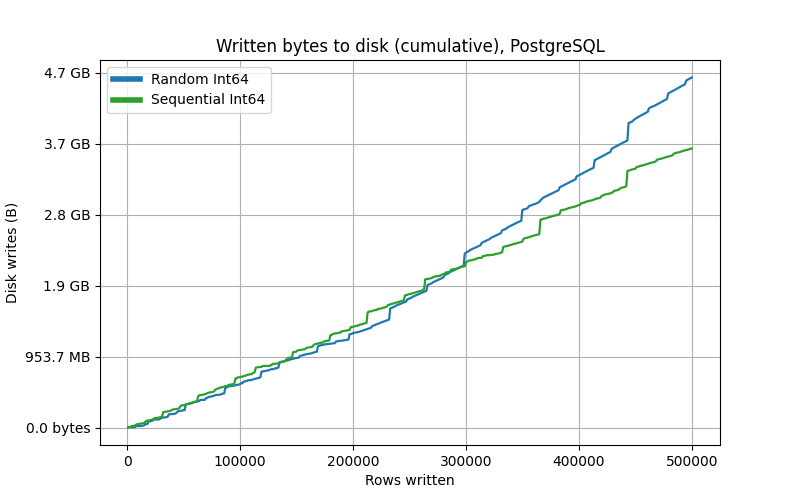
When taking the differentiated writes (per row) on a larger table, the overhead of random values is visible as well:
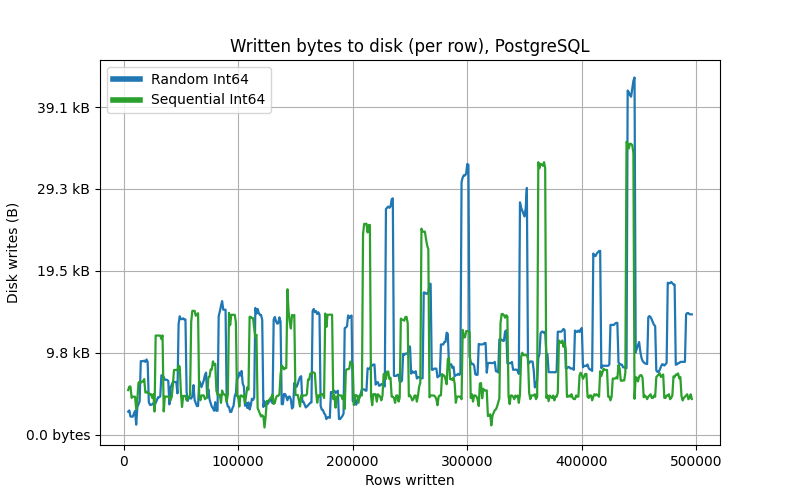
The difference is obviously less significant than on a clustered index, but it is still there.
If you want to use a random identifier or have an existing back-end application that generates random id-s, and you are free to choose a relational database, PostgreSQL will meet your needs.
Conclusion
When using a clustered index in a table that is not purely composed of index values, generating completely random values for the primary key across the full set of possible values will lead to many disk I/O operations because the page cache cannot be used effectively.
Note: A clustered index is still useful when scanning a large number of rows on a range of the primary key2, but this is unlikely to be needed with completely random identifiers.
How much I/O can be saved?
The number of saved I/O operations is not constant and it depends on the size of the index and therefore on the number of records written. The saved I/O can be estimated by taking the integral of the B-tree insert complexity for 1 insert:
\int \ln(n) \,dn = n (\ln(n) -1 ) \textcolor{grey}{ + constant}If we assume that the sequential id’s insert complexity is constant 1, the resulting ratio is as follows:
saved \,I/O\, portion \approx 1 - \frac{n}{n(\ln(n)-1)} \approx 1 - \frac{1}{ln(n)-1}When inserting one million rows into a clustered index, using a sequential primary key would save approximately 92% of I/O volume.
UUIDs
Universally Unique Identifiers (UUIDs) have a couple of advantages over sequential id-s generated by the RDBMS (AUTOINCREMENT, SERIAL), mainly that they can be generated prior to sending the insert query to the DB. Unfortunately, InnoDB with its clustered index is one of the most popular storage engines. Using it with UUIDs, which are random by-design, leads to excess disk I/O, which is non-trivial to avoid.
I’ve written more about the use of UUID-s in the next article of this series: How UUIDs Hurt B-Tree Performance and What Can Be Done About It
Trudeau, Y. (2019, November 22). UUIDs are Popular, but Bad for Performance — Let’s Discuss. Percona Database Performance Blog. https://www.percona.com/blog/2019/11/22/uuids-are-popular-but-bad-for-performance-lets-discuss/
Coburn, M. (2015, April 2). Illustrating Primary Key models in InnoDB and their impact on disk usage. Percona Database Performance Blog. https://www.percona.com/blog/2015/04/03/illustrating-primary-key-models-in-innodb-and-their-impact-on-disk-usage/
Vondra, T. (2019, February 28). Sequential UUID Generators. 2ndQuadrant | PostgreSQL. https://www.2ndquadrant.com/en/blog/sequential-uuid-generators/
Nanoglyph. (n.d.). Identity Crisis: Sequence v. UUID as Primary Key. https://brandur.org/nanoglyphs/026-ids
- This is an instance of security through obscurity, but it can be advantageous in terms of performance and ease-of-use (simpler API). [↩]
- https://www.guru99.com/clustered-vs-non-clustered-index.html#:~:text=used%20in%20joins.-,Advantages%20of%20Clustered%20Index,-The%20pros/benefits [↩]
What a great article! I scrolled across google and SO to understand why exactly random UUIDs can be inefficient and it has only clicked with this article. Love the math to calculate the actual disk IOPS saved by sequential IDs.
Thank you for reading! I’m glad it was useful.